웹을 이루는 기술HTTP 소개
페이지 정보
관련링크
본문
연재글
- 2. Reverse Proxy
- 1. HTTP 소개
HTTP 소개
인터넷상에는 수많은 애플리케이션이 있다. 이들 애플리케이션은 데이터를 주고 받기 위한 "데이터 형식"이 있는데, 이를 프로토콜이라고 한다. 프로토콜은 지켜야할 규약이다. 즉 애플리케이션을 개발하기 위한 "규약"이다.
인터넷상에서 파일을 주고 받기 위해서는 FTP 규약이 필요하고, 메일을 주고 받기 위해서는 SMTP, 도메인이름을 사용하기 위해서는 DNS규약에 따라서 애플리케이션을 개발해야한다.
HTTP도 인터넷에서 사용하는 여러 프로토콜 중 하나다. 각 프로토콜은 고유의 목적이 있는데, HTTP는 인터넷 상에서 "문서와 파일"을 주고 받는 것을 목적으로 한다. HTTP는 특히 인터넷에서 가장 유명한 그리고 가장 성공한 프로토콜일 것이다.
애플리케이션 개발자들은 프로토콜을 이용해서 애플리케이션을 개발하는데, HTTP를 기반으로 만든 애플리케이션이 바로 "웹서버(NginX, Apache 등)"과 "웹 브라우저(Chrome, Firefox, Edge...)" 다. 현대 생활을 살아가는 사람이라면 개발자이든 아니든 거의 매일 HTTP를 사용하고 있다고 보면 되겠다.
거의 모든 인터넷 애플리케이션들이 HTTP를 직/간접적으로 이용하고 있기 때문에, 인터넷 개발자라면 HTTP를 필수적으로 이해해야만 한다.
인터넷의 아버지 - Tim Berners-Lee

HTTP는 팀 버너리스 경이 최초 설계와 개발에 참여했다. HTTP 뿐만 아니라, HTML, URL, 하이퍼텍스트 시스템의 설계와 개발에도 참여했기 때문에 인터넷의 아버지(혹은 웹의 버지)라고 부르기도한다. 인터넷 세상에서는 가장 중요한 인물 중 한명일 것이다.
HTTP의 작동 구조
HTTP는 서버/클라이언트 모델을 따르는 프로토콜이다. 서버는 (HTML, CSS, JavaScript)문서, 이미지, 동영상 등을 저장하고 있다가 클라이언트(웹 브라우저)가 요청하면 정보를 서비스한다. 아래 이미지는 HTTP의 작동방식을 묘사하고 있다.

- 클라이언트는 HTTP 규약에 따라서 요청을 만든다. 예를들어 웹 브라우저 주소창에 http://httpd.co.kr/index.html 를 입력했다면, 웹 브라우저는 서버에 index.html 문서를 다운로드 해달라고 요청을 보낸다.
- 서버는 클라이언트의 요청을 읽어서 해석한다. 이 요청에는 index.html 문서를 달라는 등의 정보가 포함되어 있다. 그러면 서버는 하드디스크나 데이터베이스에서 index.html 문서를 찾아서 응답을 보낸다.
- 클라이언트는 다운로드한 index.html 문서를 브라우저에표시한다. 웹 브라우저는 HTML로 된 문서를 랜더링 할 수 있는 기능을 포함하고 있다. 이 기능을 이용해서 하이퍼 링크, 텍스트, 이미지를 화면에 출력한다.
HTTP 요청(Request)의 구조
HTTP는 서버/클라이언트 모델을 따른다고 했다. 클라이언트는 요청(Request)를 하고 서버는 응답(Response)를 합니다. HTTP는 요청과 응답으로 구성된다는 것을 알 수 있다. 그 중 HTTP 요청을 살펴보자. 요청은 크게 "Header"와 Body로 구성된다.
Body에는 요청 데이터 본문이 들어간다. 어떤 사이트에 가입을 가입을 하기 위해서 가입 신청서를 제출한다면 Body에는 "이름", "닉네임", "이메일주소","주소" 등이 들어갈 것이다.
Header에는 요청 데이터에 대한 정보와 요청을 처리하기 위한 갖가지 정보들이 들어간다. 아래는 헤더의 일반적인 모습이다.
[code]
POST /user/info HTTP/1.1
HOST: www.joinc.co.kr
ACCEPT_ENCODING: gzip,deflate,sdch
CONNECTION: keep-alive
ACCEPT: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
ACCEPT_CHARSET: windows-949,utf-8;q=0.7,*;q=0.3
USER_AGENT: Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24
ACCEPT_LANGUAGE: ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4
[/code]
헤더는 매우 많은 정보들을 포함 할 수 있는데, 지금은 필수적인 것들만 살펴보겠다.
- 요청 메서드(Method) : GET, PUT, POST, DELETE, OPTIONS, HEADER 등의 메서드가 있다. 이 메서드는 서버에 "나 어떤 행동을 할 거야"를 알려주기 위해서 사용한다. GET이라면 "다운로드", POST는 "업로드", PUT은 "업데이트(수정)", "DELETE"는 삭제 입니다. 위 예제네서는 POST를 사용했다.
- 요청 URI : 호출 할 페이지다(혹은 자원이라고 하기도 한다. 문서만 호출하는게 아니니 자원이라고 하는게 오히려 직관적이다). 예제에서는 /user/info 페이지를 호출하고 있다. 메서드가 POST 이니, 대략 유저 정보를 제출하는 요청이라고 예상 할 수 있다.
- HTTP 프로토콜 버전 : 애플리케이션은 진화한다. 이 진화의 과정을 버전으로 표현한다. 프로토콜도 애플리케이션의 변화에 맞추어 진화하며 버전을 가진다. 예제에서 클라이언트는 HTTP 버전 1.1의 규약에 맞춰서 요청서를 작성했음을 알 수 있다. 2021년 현재 HTTP/1.1을 가장 널리 사용하고 있으며, 차세대 프로토콜인 HTTP/2를 함께 사용하고있다
- HOST : 어떤 호스트에 요청을 했는지를 설정한다. 하나의 서버가 여러 사이트를 서비스 할 수 있는데, 이 정보를 이용해서 요청을 정확히 전달 할 수 있다. 또한 SSL 인증서는 HOST 이름을 기반으로 만들어지기 때문에, 서버를 인증하기 위한 중요 정보로도 사용한다.
HTTP는 다양한 인터넷 애플리케이션의 개발을 위해서 만들어진 프로토콜이다. 따라서 본문(body)에는 HTML, XML, JSON, 비디오, 오디오, 이미지, 스트리밍.. 어떤 데이터라도 처리 할 수 있다.
응답 포맷
서버는 클라이언트의 요청을 받아서 처리한 결과를 HTTP 응답으로 리턴한다. 응답 역시 헤더와 본문으로 구성된다.
[code]
HTTP/1.1 200 OK
Date: Fri, 08 Jul 2011 00:59:41 GMT
Server: Apache/2.2.4 (Unix) PHP/5.2.0
X-Powered-By: PHP/5.2.0
Expires: Mon, 26 Jul 1997 05:00:00 GMT
Last-Modified: Fri, 08 Jul 2011 00:59:41 GMT
Cache-Control: no-store, no-cache, must-revalidate
Content-Length: 102
Keep-Alive: timeout=15, max=100
Connection: Keep-Alive
Content-Type: text/html
[/code]
핵심 정보들만 간추려서 살펴보자.
- 첫줄에는 HTTP 버전과 상태코드(Status Code)를 반환한다. 클라이언트가 HTTP/1.1로 요청을 했으니, 서버도 HTTP/1.1로 응답했다.
- 200 OK는 상태 코드와 메시지다. 이 값을 이용해서 서버가 요청을 잘 처리했는지, 어떤 문제인지를 대략 확인 할 수 있다. 예를 들어 200은 요청을 성공적으로 처리했음, 404는 페이지가 없음, 500 은 서버에러(애플리케이션의 오작동)을 의미한다.
- Content-Length는 컨텐츠(본문)의 크기를 나타낸다.
- Content-Type는 컨텐츠의 형식을 나타낸다. text/html은 html 문서를 의미한다. 요즘에는 JSON 형태로 응답하는 경우가 많은데, 이 때는 Content-Type를 Application/json으로 설정하면 된다. 클라이언트는 Content-Type의 정보를 이용해서 본문 데이터를 어떻게 처리 할지를 알 수 있게 된다.
기타 Cache-control, Keep-Alive, Connection 등의 생소한 헤더 정보들이 있다. 이들은 따로 자세히 다루도록 하겠다.
URI
URI(통합자원식별자)는 Uniform Resource Identifiers의 줄임말이다. 인터넷에는 전 지구에 걸쳐서 엄청나게 많은 양의 문서, 이미지, 영상이 흩어져 있다. 원하는 자원을 찾기 위해서는 자원을 위치를 찾고 자원을 식별 할 수 있어야 한다. 인터넷상에서 자원을 식별하기 위해서 사용하는 것이 URI다. 애플리케이션은 URI를 이용해서 인터넷상에서 유일한 자원을 식별 할 수 있다. URI의 포맷은 다음과 같다.
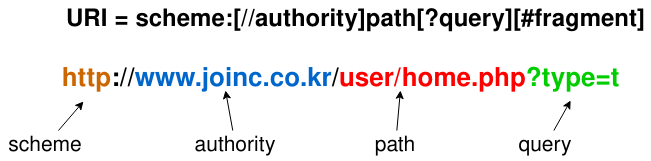
해석하자면 이렇다. http 스키마를 사용하는 자원이다. authrity는 [userinfo@]호스트[:port]로 구성된다. userinfo와 port는 생략하는게 보통이다. port가 생략될 경우 각 프로토콜의 기본 port가 사용된다. http는 80, https는 443, ftp는 21이다. 기본 포트를 사용하지 않은 경우에는 example.com:8080과 같이 포트를 명시하기도 한다.
HTTP 상태 코드(Status Code)
당신이 인터넷 서비스 개발자라면 HTTP 응답 코드를 이용해서 에러를 처리하고 디버깅을 해야 할 것이다. 라이브러리를 사용 할 때, 에러코드를 중요하게 보듯이 HTTP에서도 에러코드는 매우 중요한 정보다.
HTTP 상태 코드는 숫자로된 코드와 사람이 이해하기 쉬운 상태 메시지로 구성된다.

아래 중요 HTTP 상태 코드들을 정리했다.
1xx
HTTP 요청은 수신이 됐고, 다음 처리를 계속 해야 함을 의미한다. 인터넷 애플리케이션을 개발하면서 1xx 코드는 거의 사용하지 않을 것이다. 나 역시 한번도 사용해본적이 없다.
2xx 성공
서버가 요청을 성공적으로 처리했음을 의미한다
| 코드 번호 | 설명 | 비고 |
| 200 | 성공 | 서버가 요청을 잘 처리했다. |
| 201 | 생성됨 | 서버가 요청을 잘 처리했으며, 새로운 리소스를 만들었다. |
| 202 | 허용됨 | 요청을 받았으나 아직 처리하지 못했다. |
| 204 | 컨텐츠 없음 | 요청을 처리했지만, 컨켄츠를 제공하지 않는다. |
| 205 | 컨텐츠 재 설정 | 요청을 처리했지만, 컨텐츠를 표시하지 않는다. 그리고 문서를 재 설정할 것을 요구한다. |
| 207 | 일부 성공 | 요청의 일부만 성공적으로 처리 |
HTP는 폭넓게 사용 할 것을 목표로 하고 있기 때문에, 예상 할 수 있는 다양한 상황들에 대한 코드를 만들어뒀다. 하지만 실제 애플리케이션을 개발하다보면 200 외에는 사용 할 일이 거의 없을 것이다. 성공에 대한 상세 내용을 알려줘야 한다면 본문에 추가 정보를 넣는게 요즘 추세다.
3xx 리다이렉션
때때로 요청의 처리를 완료하기 위해서, 다른 페이지로 보내야 할 때가 있다. 예를 들어 로그인을 성공하고 나서, 사용자 페이지로 보내거나 HTTP 요청을 HTTPS로 보내거나, 페이지를 요청하지 않은 경우 index.html 보내는 등이다.
| 코드 번호 | 설명 | 비고 |
| 300 | 여러 선택 항목 | |
| 301 | 영구 이동 | 요청한 페이지가 다른 위치로 영구 이동했다. |
| 302 | 임시 이동 | 요청한 페이지가 다른 위치로 임시 이동했다. 요청자는 여전히 이 페이지를 요청해야 한다. |
| 303 | 기타위치보기 | 요청자가 다른 위치에 별도의 GET 요청을 하여 응답을 하는 경우 |
| 304 | 수정되지 않음 | 마지막 요청 이후 요청한 페이지가 수정되지 않았다. if-Modified-Sine 헤더에 지정된 날짜/시간 이래로 지정된 문서가 변경된 사실이 없는 경우 리턴한다. |
| 305 | 프록시 사용 | 요청자는 프록시를 사용해야 페이지에 접근 할 수 있다. |
301 이외에는 그냥 이런게 있나보다 정도로만 이해하고 넘어가면 된다.
4xx 요청 오류
실패 값을 리턴하다보니 개발 할 때, 가장 많이 접하는 상태 코드다.
| 코드 번호 | 설명 | 비고 |
| 400 | 잘못된 요청 | 요청 포멧이 HTTP 규약에 맞지 않는 경우 |
| 401 | 권한 없음 | 인증이 필요하다. Basic access authentication에 사용한다. |
| 403 | 금지 | 서버가 요청을 거부하고 있다. 주로 애플리케이션에서 사용자 인증에 실패해서 권한이 없을 때. |
| 404 | 찾을 수 없음 | 요청판 페이지가 서버에 존재하지 않는다. |
| 405 | 허용하지 않는 메서드 | 허용하지 않는 메서드(PUT, POST 등) |
| 406 | 허용하지 않음 | 요청한 페이지를 어떤 이유로 응답 할 수 없다. |
| 408 | 요청시간 초과 | 서버의 요청 대기 시간 초과 |
| 410 | 사라짐 | 요청한 자원이 삭제돼었음. 404와 비슷하다. 요즘에는 사용하지 않는다. |
| 411 | 길이필요 | 컨텐츠의 길이(Content-Length)를 명시해야 한다. |
주로 접하는 코드는 400, 403, 404, 408 이다. 404는 인터넷 서핑을 하다보면 자주 보게 되는 코드다.
403은 로그인이 필요한 자원(이미지, 문서)에 로그인 없이 접근 할 때, 리턴하는 에러다.
408은 서버의 요청 대기 시간이 초과 했을 때 리턴한다. HTTP는 Connectless & Stateless 프로토콜이다. 서버는 작업이 완료되면 다음 작업을 기다리지 않고 즉시 연결을 끊는 식으로 작동한다. 만약 처리시간이 지나치게 길어지면, 서버는 작업 완료되기 전이라도 연결을 닫아버리고 408을 리턴한다. 나중에 살펴보겠는데, 일반적으로 웹 애플리케이션은 중간에 하나 이상의 HTTP 프락시를 경유하고 이들도 408을 리턴 할 수 있기 때문에 문제 해결을 어렵게 하기도 한다. 예를 들어서 우리 서비스는 커다란 파일을 다루기 때문에 최대 10초를 기다리도록 설정 했는데, 그 앞단에 있는 HTTP 프락시는 기본 값인 3초로 되어 있을 수 있다. 이 경우 빈번한 408 에러가 발생 할 것이다.
500 Internal Server Error
애플리케이션 버그, 데이터베이스 문제, 기타 시스템/네트워크 문제로 요청을 처리 할 수 없을 때, 혹은 요청 처리 중에 실패가 발생했을 때 리턴하는 상태 값이다. 500 에러가 발생했다는 것은 서버가 제대로 작동을 못한다는 것을 의미하므로, 서비스 운영자와 개발자가 매우 바뻐진다.
Connectless 와 Stateless
여러 유저가 참여해서 실시간으로 통신하는 인터넷 온라인 게임의 경우에는 한번 연결을 맺으면, 로그아웃 할 때까지 계속 연결을(Connect) 맺는다. 예를들어 게임에 접속했을 때 TCP 연결을 한번 맺으면 접속을 끝낼때까지 연결을 계속사용하는 방식이다.
반면 HTTP는 기본적으로 요청단위로 새로운 연결을 만들고, 연결을 끊는다. 어떤 사이트에 HTML 문서를 요청했다고 가정해보자. 이 HTML 문서는 HTML 텍스트와 이미지, CSS, 자바스크립트 약 10개의 요소를 가지고 있다. 이 경우 웹 브라우저는 한번의 연결에서 10번 요청을 하고 끝내는게 아니고, 10번 연결을 하고 연결을 끊는다. 연결을 유지하지 않는 Connectless 방식인 것이다.
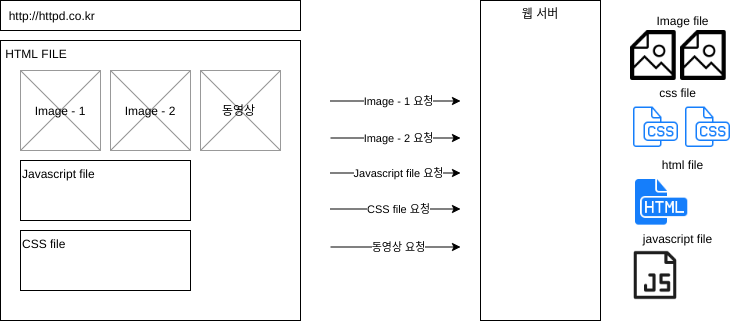
HTML 문서 하나 출력하는데, 10번의 새로운 연결/요청을 만들어야 한다. 100개의 요청이 있다면 100번 새로운 연결/요청을 만들어야 한다. 당연히 비효율적인(TCP/IP 통신에서 연결에는 매우 많은 비용이 들어간다.) 방법이다. 이렇게 비효율적으로 만들어진 이유는 HTTP가 문서를 공유하기 위한 목적이었다는데 있다. 요청한 문서를 다운 받으면 작업이 끝나는 거니까. 굳이 연결을 유지 할 필요가 없었던 것이다. HTTP가 만들어졌던 1990년 초에는 문제가 없었으나, 모든 정보가 인터넷을 통해서 유통되는 지금 문제가 되는 것이다. 물론 HTTP도 놀고 있는 것은 아니라서 버전을 계속 업데이트하면서 문제를 해결(완화)하고 있다.
HTTP는 stateless 다. 상태를 유지할 필요가 없다는 의미다. 각 요청은 다른 요청과 독립적으로 작동한다. 즉 이전 요청에서 무슨 일이 있었는지 알 수 없다. HTTP의 최초목적인 문서의 다운로드에서는 문제가 없는데, 요즘에는 문제가 될 수 있다. 예를 들어 로그인 시스템을 가지고 있는 서비스라면, 이 요청이 이전에 로그인한 유저의 요청인지, 로그아웃한 유저의 요청인지 등에 대한 "상태"를 알고 있어야 한다. 요청과 요청이 서로 상태를 공유해야 하는 것이다.
HTTP는 Cookie라고 하는 데이터 조각을 서버와 클라이언트가 주고 받는 것으로 상태를 교환한다. 예를들어 로그인을 성공했다면, 서버는 클라이언트에게 로그인 했다는 것을 인증 할 수 있는 특별한 값(유추하기 힘든)을 전달한다. 클라이언트는 다음번 요청에 이 값을 HTTP 헤더에 Cookie 형태로 전달한다. 서버는 이 값을 확인해서 로그인한 유저인지 등을 판단할 수 있게 되는 것이다.
Cookie
HTTP는 무상태(stateless) 프로토콜로 다른 요청의 상태를 알 수 없다. HTTP는 쿠키(Cookie)를 이용해서 상태를 관리한다. 원리는 간단하다. 서버가 현재 요청의 상태를 담고 있는 정보를 클라이언트가 건내주고, 클라이언트는 다음 요청을 보낼 때 이 정보를 서버에게 보내는 것이다.
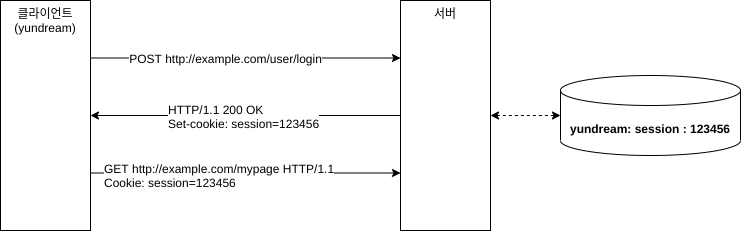
yundream 아이디를 가진 클라이언트가 example.com에 로그인을 한다. 아이디와 패스워드를 입력했을 것이고, 로그인 성공했다. 서버는 이 정보를 데이터베이스에 저장하고, Set-cookie에 쿠키 데이터를 담아서 응답한다. 이 쿠키 데이터에는 yundream 유저 정보를 조회할 수 있는 값이 들어 있다.
응답을 받은 브라우저는 Set-cookie에 있는 데이터를 저장한다. 이 데이터는 "domain, value" 형태로 저장이 된다. 즉 "example.com, session-123456" 과 같은 형태로 저장이 된다. 이제 브라우저가 example.com에 요청을 보내면, session-123456을 쿠키 데이터로 전송을 한다.
서버는 쿠키의 값을 읽어서, 유저의 최근 상태를 읽어오고 이 유저가 로그인한 유저라는 것을 알게 된다. 쿠키는 도메인과 만료 기간 같은 옵션을 제공한다.
Keep-Alive
HTTP는 connectless 프로토콜이다. 웹 페이지 하나를 표현하기 위해서 수십번의 연결을 해야 하는 (지금은) 비효율적인 프로토콜이다. HTTP 1.1 에서는 keep-alive 를 이용해서 이 문제를 해결 하고 있다.
Keep-alive 설정을 하면, 지정된 시간동안 연결을 끊지 않고 요청을 연속해서 보낼 수 있다. 아래와 같이 작동한다.
- 웹 서버에 연결한다.
- HTML 문서를 다운로드 한다.
- Imge, css, javascript 링크를 읽어서, 이들 자원을 다운로드 한다.
- 모든 문서를 다운로드 받았다면 연결을 끊는다.
HTTP 1.1 을 지원하는 웹브라우저(모든 웹브라우저가 HTTP 1.1을 지원한다)로 웹 서버에 요청을 전송하면 kepp-alive 방식으로 연결 할 것을 자동으로 설정한다.
[code]
Connection: keep-alive
[/code]
웹 서버가 keep-alive를 지원하도록 설정했다면, 응답 헤더에 keep-alive 정보를 설정해서 전송한다.
[code]
Connection: Keep-Alive
Keep-Alive:timeout=5, max=100
Content-Encoding:gzip
Content-Length:5933
Content-Type:text/html
[/code]
- Connection: Keep-Alive. Keep-Alive 상태로 연결을 유지한다.
- Keep-Alive:timeout=5, max=100. 이 연결은 최대 5초동안 유지한다. 연결이 닫히기 전까지 최대 100개의 요청을 전송할 수 있다.
예제로 살펴보는 HTTP
여러분이 웹 애플리케이션 개발자라면 반드시 알고 있어야 3개의 툴이 있다.
- CURL
- Chrome 개발자 도구
- Postman
curl을 이용해서 실제 HTTP로 어떻게 요청하고 응답을 받는지를 테스트해보자. 각각의 툴들은 별도의 강좌로 다루도록 하겠다.
[code]
# curl http://www.joinc.co.kr -i
HTTP/1.1 301 Moved Permanently
Server: awselb/2.0 Date: Thu, 24 Jun 2021 15:18:34 GMT
Content-Type: text/html
Content-Length: 134
Connection: keep-alive
Location: https://www.joinc.co.kr:443/
[/code]
-i 옵션을 이용하면 웹 서버의 응답 헤더와 본문을 확인 할 수 있다.
- HTTP 1.1 버전을 사용하고 있다.
- 응답 코드는 301 이다. 301은 다른 페이지로 자원이 이동했음을 의미한다.
- Location으로 이동한 자원의 위치를 알 수 있다. 결국 브라우저는 https://www.joinc.co.kr:443 으로 이동한다.
- Content-Type. 본문의 문서타입읜 text/html 이다.
요청은 디버깅 옵션인 -v로 확인 할 수 있다. 디버깅 모드이므로, 요층과 응답 모두를 출력한다. 웹 애플리케이션에 문제가 생겼다 싶을 때 유용하게 써먹을 수 있다. 응답은 생략했다.
[code]
# curl http://www.joinc.co.kr -i
HTTP/1.1 301 Moved Permanently
Server: awselb/2.0 Date: Thu, 24 Jun 2021 15:18:34 GMT
Content-Type: text/html
Content-Length: 134
Connection: keep-alive
Location: https://www.joinc.co.kr:443/
[/code]
- GET 메서드를 사용해서 / 페이지를 요청했다.
- HTTP 1.1 버전을 사용한다.
- 요청을 전송할 호스트의 이름은 www.joinc.co.kr이다.
- 요청에 사용한 클라이언트 프로그램(User-Agent)는 curl 이다.
[code]
# curl https://httpd.co.kr -I
HTTP/2 200
date: Thu, 24 Jun 2021 15:34:57 GMT
server: Apache
x-powered-by: PHP/7.2.33
p3p: CP="ALL CURa ADMa DEVa TAIa OUR BUS IND PHY ONL UNI PUR FIN COM NAV INT DEM CNT STA POL HEA PRE LOC OTC"
expires: 0
cache-control: pre-check=0, post-check=0, max-age=0
pragma: no-cache
set-cookie: PHPSESSID=ple9lc58iikub8b9jrd6b0b5v5; path=/
set-cookie: 2a0d2363701f23f8a75028924a3af643=MTE2LjEyNy40Mi4yMzg%3D; expires=Fri, 25-Jun-2021 15:34:57 GMT; Max-Age=86400; path=/
last-modified: Thu, 24 Jun 2021 15:34:57 GMT
access-control-allow-origin: *
content-type: text/html; charset=utf-8
[/code]
-I 옵션을 이용하면 응답 헤더만 볼 수 있다.
- HTTP/2 를 지원하는 서버다. HTTP/2는 HTTP/1.1을 하위 호환한다.
- set-cookie를 이용해서 쿠키를 전송하고 있다.
- x-powered-by : HTTP 헤더는 커스텀(사용자) 필드를 허용한다. 커스텀 필드를 이용해서 애플리케이션을 다양하게 확장 할 수 있다.
정리
이상 http 에 대해서 살펴봤다. 여기에서는 http의 기본정보만을 소개했다. 당신이 클라이언트 개발자든 백앤드 개발자이든 웹 애플리케이션을 개발한다면 http에 대해서 충분히 숙지 할 필요가 있다. 개발자들과 원할히 소통 할 수 있으며, 문제를 더 빠르게 찾아내고 해결책을 제시 할 수 있을 것이다. REST API등을 개발 한다고 하면, API 명세서를 작성하든 디버깅을 하든 뭘 하든지 간에 HTTP 헤더 정보를 가지고 이야기 하게 될 것이다.